なぜプログラミング言語を作るか
- 自分たちが普段使っている言語処理系が内部でどんなことを行なっているかを知る機会になる
- これを機会に複数の言語に触れると、リテラシーや知識の向上につながる
- 新しく言語を学ぶ際に、ちょっとしたJSONパーサーなどはお題としておすすめ
プログラミング言語処理の構成
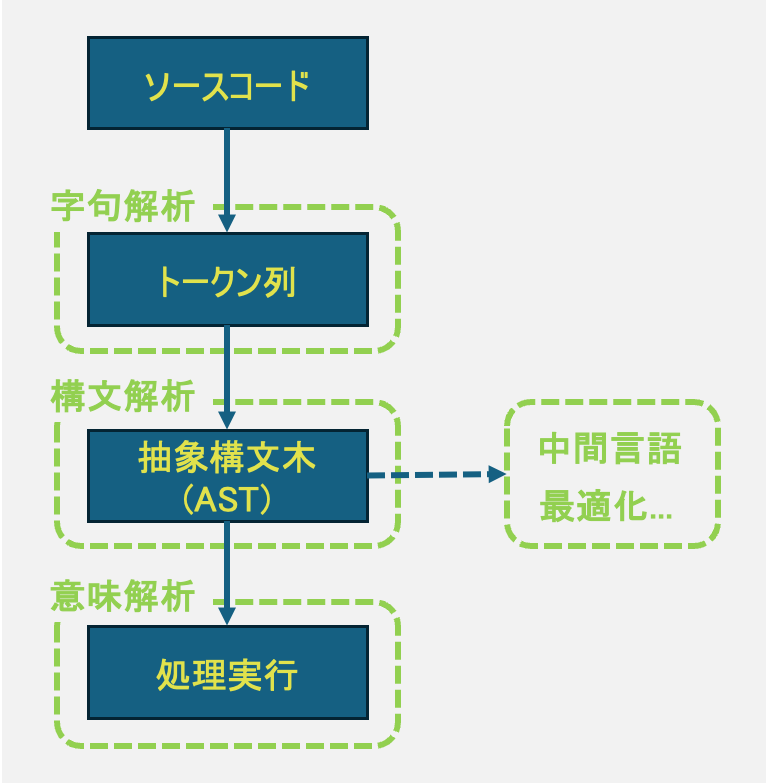
プログラミング言語のソースコードを解析して処理を実行する際には、どういった処理が行われているのでしょうか。
一般的に、ソースコードは以下のようなステップを踏んで解釈・評価されます。
- 字句解析
- 構文解析
- 意味解析
ただし、必ずこのステップに沿っていなければいけないわけではなく、こうした処理を行わない言語処理系もあります。
また、実用的な言語では、解析処理時に「処理の最適化」や「中間言語(バイトコード)」への変換を行うなどして、より効率よくプログラムを実行できるようにする場合もあります。

字句解析
「字句解析」というのは、文字列として与えられたソースコードを解析して、「プログラムを構成する最小の意味単位(トークン)への分割を行う」ステップです。
例えば、JavaScriptのプログラムを例にとると、以下のようなイメージです。
各トークンは、「(」などのように空白文字列を介さないで記述される場合もあり、次ステップでプログラムを解析することができるよう、解釈の最小単位に分割する必要があります。

| トークン文字列 | 意味 |
| function | 関数宣言の予約語 |
| calculate | ユーザー定義の関数名 |
| ( | 関数引数の開始位置用 区切り文字 |
| a | 関数の引数 |
| { | ブロックの開始位置用 区切り文字 |
| … | … |
構文解析
「構文解析」というのは、その言語処理系の文法に照らし合わせ、前段の字句解析で得られたトークン列を式・文として評価するための構造化を行う処理です。
たとえば、「10 + 20 * 30」という式の字句解析結果として以下のようなトークン列が得られた場合。

私たち人間は、式を見た際に「20 * 30 をした結果に10を加算すればいい」とすぐに解釈できます。
ところが、コンピュータの場合はそうもいきません。
1 + 2 * 3のような式の場合、2 * 3の方が優先度が高いなどの文法上の解析を行わなければ、うまく解釈できないわけです。
こうした、演算の優先度などを決めるための構造として「抽象構文木(AST)」の構築が行われます。
具体的には、トークン列から以下のようなツリー構造を生成し、それを下から解釈していけば演算の優先度に従って結果が得られるようにしてあげます。
こうしてあげると、この後の意味解析時点では、抽象構文木の構造に則って解析・評価するだけという状態になります。

また、「( )」を追加して計算処理の優先度を変更する場合は以下のような抽象構文木が形成されるでしょう。

意味解析
「意味解析」のステップでは、最終的に出来上がった抽象構文木の評価順序に従って評価を行い、最終的な出力結果を得ます。
プログラミング言語作成の参考書籍
Rustで作るプログラミング言語
リンク

サンプルコード
/factorial { 1 factorial_int } def
/factorial_int {
/acc exch def
/n exch def
{ n 2 < }
{ acc }
{
n 1 -
acc n *
factorial_int
} if
} defおすすめポイント
- Rustでプログラミング言語を作る
- 書籍を通して複数の言語を作る体験ができる
- 最初に作るスタックベースの言語(rustack)は非常にシンプルな仕様で50P弱の内容なので、気軽にできる
- 後の方では型つきの言語実装もある(未読)
Go言語で作るインタプリタ
リンク

サンプルコード
let fibonacci = fn(x) {
if (x == 0) {
0
} else {
if (x == 1) {
1
} else {
fionacci(x - 1) + fibonacci(x - 2);
}
}
};おすすめポイント
- Goでプログラミング言語を作る
- 300P弱にわたって1つの言語を作る
- ちょっとしたスクリプト言語的な結構リッチな仕上がりになるので、慣れてきたらおすすめ
今回作った言語
ある程度一般的なプログラミング言語に近いシンタックス
今回作成する言語については、あくまで練習用ということもあり、なるべく実装は小さいものにしたいと思っていました。
ただ、上述のRustackのような後置記法だと、評価は楽でもちょっと一般的なプログラミング言語と比較すると読みづらさに難があるかと思い、より一般的なプログラミング言語に近いシンタックスになるよう考慮しています。
具体的には下記のようなシンタックスです。
(def product (x acc)
(if (< x 1)
acc
(product (- x 1) (* acc x))))
(print (product 10 1))シンプルな評価ルール
上述のサンプルコードを見て「( )」が多いと思った方もいらっしゃるかもしれないですね。
このシンタックスは、LISPという言語の「S式」を参考にしています。
(print (- 2 (/ 40 (* 10 (+ 1 1)))))
(print
(- 2
(/ 40
(* 10
(+ 1 1)
)
)
)
)S式の特徴としては、構文自体がそのまま木構造になっていることで、この特徴を利用して、今回の言語ではソースコードを解釈する際に構文解析をスキップすることで、実装をシンプルにすることを心がけました。
ソースコードを左から読み込んでいき、「(」が出てきたら、対応する「)」との間のコードを内側(ネストの深いところから)から順番に評価するというシンプルなルールで処理を実行しています。

リポジトリ
まとめ
- プログラミング言語に興味があれば、上の書籍などを参考にしてみて
- 簡単なインタプリタの作成は、新しい言語の学習課題としてもぴったり
- これを機会に複数の言語に触れると、さまざまな言語の機能やリテラシーや知識の向上につながる
もし興味が湧いたよという方がいらっしゃいましたら、ぜひ自作の言語を作ってみてくださいね!
